Introduction
About this entry
This blog post is an introduction to the Signature Model approach to function calling.
The following repository contains a collection of tutorials presented as Jupyter Notebooks:

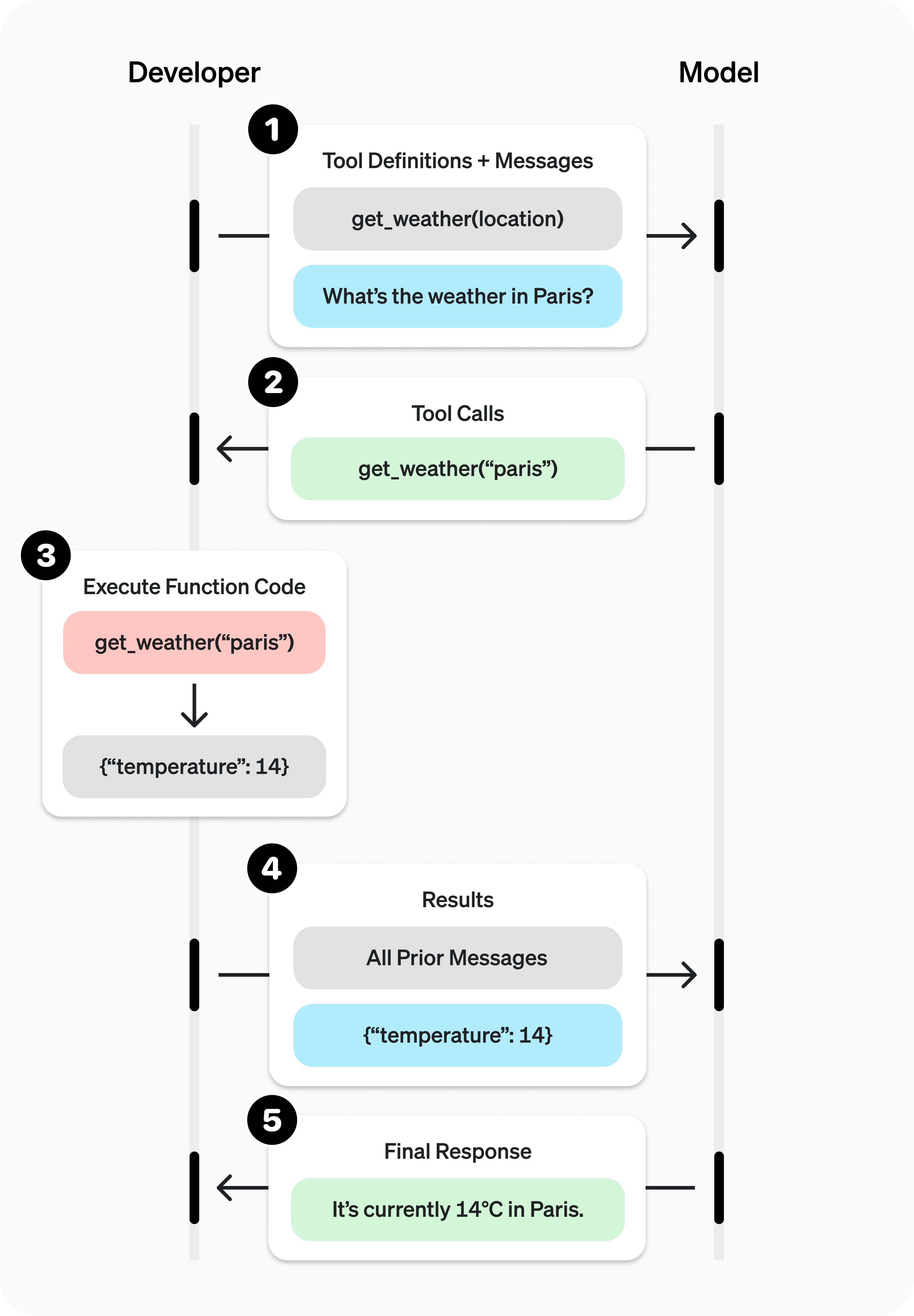
Function calling is at the heart of developing agents and agentic workflows. It consists in providing an LLM with the definition of some tools, that is to say, what is the name of the tools, its description, what are its parameters and parameters’ types, etc. The definition is usually done using OpenAPI specifications (or at least a subset of it). Once provided, a LLM can decide to return one or several tool calls, that is to say, indicate to the caller that to answer the question he/she should call the tool with the provided parameters.
For instance, as illustrated by the figure below, if we provide a tool get_weather(location: str) with the description “Use this tool to get the weather of a given location”, we can expect the LLM to answer to the question “What’s the weather in Paris” by a tool call get_weather("Paris").
It is important to understand that the LLM only returns the function name and the concrete value of its parameters. It is on the caller to properly call the function locally to get the result. The LLM does not know the concrete implementation of get_weather nor its return type.
Despite being absolutely essential to develop agents, the current state of function calling is rather poor. Developers are often constrained by LLM providers, and despite similar interfaces across major platforms, tool signature support varies significantly. For example, while all providers may claim supporting function calling, they often implement only a subset of OpenAPI specifications which is a problem to develop LLM agnostic agent.
Beyond this purely technical issue, there are also many limitations with the current function calling mechanism:
- the function calling mode is usually limited to any (call zero or one) or required (call at least one) with a few variations depending on the provider.
- the execution is limited to parallel function calling, that is to say, the LLM returns a list of function to be called in parallel and therefore, there is no notion of dependencies between the functions (e.g. the input of a function must be the output of a previous one).
- depending on the model, very few functions can be returned at once.
These limitations are only due to the implementation of the function calling mechanism by the LLM providers rather than a technical limitation.
In fact, last time, I was listening to an interview of Arthur Mensch, the CEO of Mistral, who talked about this issue as one key problem to solve in order to unlock the next level of agents. And this is a problem I often faced at Proofs: to solve a task, an LLM decides to call two tools, A and B, but the input of B depends on the result of the execution of A. The LLM clearly identified the correct tools and parameters, but the tooling around function calling does not support this sort of mechanism.
To give a concrete example, imagine that an Agent needs to be obtain a token from some upload service (tool A), then generate an image (tool B), upload the image to the service using the token to authenticate (tool C) and finally send the uploaded image via email to a customer (tool D).
All current SotA LLMs are theoretically capable of handling this task. However, none of them allows in one LLM call to execute perfectly the tools to achieve the goal. This is because to provide the argument of tool D, the output of tool C needs to be known by the LLM, and for tool C, we need the output of tool A.
Here is an illustration with o1 for the request “First, generate an image of Krakow. Then, upload it to our backend and then share it to our favorite customer”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38 | ChatCompletion(
id='chatcmpl-B6Ix1aCx071kDd4FtYIpgpF0E9J7C',
choices=[
Choice(
finish_reason='tool_calls',
index=0,
logprobs=None,
message=ChatCompletionMessage(
content=None,
refusal=None,
role='assistant',
audio=None,
function_call=None,
tool_calls=[
ChatCompletionMessageToolCall(
...
function=Function(
arguments='{\n "comment": "Generate an image of Krakow",\n "image_description": "Photo-realistic aerial view of Krakow city with its famous old town, a beautiful daytime sky, and
high-quality details.",\n "output_path": "krakow.png"\n}',
name='generate_image'
),
type='function'
)
]
)
)
],
...
model='o1-2024-12-17',
...
usage=CompletionUsage(
completion_tokens=462,
prompt_tokens=310,
total_tokens=772,
completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=384, rejected_prediction_tokens=0),
prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)
)
)
|
In this case, the LLM only returned the first tool despite being prompt for a bigger task. As a developer I could either change the prompt to enforce more tools, call again the LLM in a multi-turn discussion with the history. I am also not able to know if the LLM returned only one call because it “thinks” this is all that is needed to fulfill the task.
With Sonnet 3.7, we at least get the indication that we will need to call the LLM several times. Better, but not optimal for our wallet!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | Message(
id='msg_01TR5ePsicDHk67Fd98DkVsL',
content=[
TextBlock(
text="I'll help you generate an image of Krakow, upload it to the backend, and share it with your favorite customer. I'll need to use several tools in sequence to complete this request.\n\nFirst, let me
generate the image of Krakow:",
type='text'
),
ToolUseBlock(
id='toolu_01YLoBkBgK2NG5JB4XqtZjW3',
input={
'comment': 'Generating an image of Krakow as requested by the user',
'image_description': "A beautiful panoramic view of Krakow, Poland, showing the historic Old Town with St. Mary's Basilica, Wawel Castle, the Vistula River, and colorful Renaissance architecture
under a clear blue sky",
'output_path': 'krakow_image.jpg'
},
name='generate_image',
type='tool_use'
)
],
model='claude-3-7-sonnet-20250219',
role='assistant',
stop_reason='tool_use',
stop_sequence=None,
type='message',
usage=Usage(input_tokens=893, output_tokens=215, cache_creation_input_tokens=0, cache_read_input_tokens=0)
)
|
To overcome this problem, I have developed a solution that emulates the syntactic sugar of function calling via structured output. In other words, the function calling mechanism itself is defined on the client side, and the only expected capability from the LLM is good support for structured output. As I will demonstrate at the end of this article, the task described above can be fully handled in one single LLM call thanks to this solution.
More generally, this approach offers several benefits:
- Control Over Tool Selection: Better management of how many tools are called.
- Runtime Contextual Information: Leverage contextual data without modifying prompts.
- Complex Parameter Types: Support Pydantic objects as input parameters, a feature no provider currently supports.
- Function Dependencies: Manage dependencies between functions, use outputs from one function as inputs for another without re-calling the LLM.
- Client Side Customization: Adjust the features of the function calling based on the use-case, for instance, enhance observability.
For the remainder of this article, I will refer to current server-side function calling as “native function calling” and my solution using structured output exclusively as “signature model function calling.”
I assume that the LLM fully supports OpenAPI 3.0 specifications for structured output. This can be achieved through coalescence technique developed by Outlines and available in vLLM and other inference servers, or a more traditional prompting approaches like the one used by Instructor.
From Functor to Signature Model
The core idea is to automatically convert a Python function’s signature into a Pydantic model which itself is compliant with OpenAPI 3.0 specifications. By aggregating these models into a type union, we simulate a set of functions the LLM can select from and instantiate with specific values.
To be able to hold more information about the signature, we use functors. Let’s create a BaseFunction class that all our functions inherit from:
| class RandomIntFunction(BaseFunction):
name = 'get_random_int'
description = "A function that returns a random integer between a specified lower and upper bound."
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
"lb": "Lower bound",
"ub": "Upper bound"
}
def __call__(self, lb: int, ub: int) -> int:
return randint(lb, ub)
|
In addition to the implementation in __call__, we add the description of the function and its parameters, as well as a more Pythonic name to the function. This would allow, with slightly more work, to be fully compatible with native function calling, i.e., to be natively supported by the OpenAI client and other clients with a similar interface. This is for instance what we have done at Proof where our unified LLM client supports native function calling and signature function calling interchangeably.
We need a mechanism to convert BaseFunction instances into Pydantic models representing their signatures. Python’s inspect module helps manipulate method signatures, and Pydantic’s create_model dynamically generates models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | from inspect import signature, Signature
from pydantic import BaseModel, create_model, Field, ConfigDict
from collections import defaultdict
def to_function_signature_model(function: BaseFunction) -> BaseModel:
# Remove `self` from the signature
S = signature(function.__call__, follow_wrapped=True)
params = [p.replace() for n, p in S.parameters.items() if n != 'self']
new_s = Signature(parameters=params, return_annotation=S.return_annotation)
# Build the field with the available info from the signature and the object itself
pydantic_fields = {k:defaultdict() for k in new_s.parameters.keys()}
for param_name, param in new_s.parameters.items():
if desc := function.properties.get(param_name):
pydantic_fields[param_name]['description'] = desc
if param.default != Signature.empty:
pydantic_fields[param_name]['default'] = param.default
model: BaseModel = create_model(
function.name,
__config__=ConfigDict(json_schema_extra={'description': function.description.strip(), 'test_field': 'this is a test'}),
**{param_name: (param.annotation, Field(**pydantic_fields[param_name])) for param_name, param in new_s.parameters.items()}
)
return model
|
When applied to RandomIntFunction, this produces a nice Pydantic model that can be converted into an OpenAPI schema:
1
2
3
4
5
6
7
8
9
10
11
12
13 | fsm = to_function_signature_model(RandomIntFunction)
print(fsm, type(fsm))
print(fsm.model_json_schema())
<class '__main__.get_random_int'> <class 'pydantic._internal._model_construction.ModelMetaclass'>
{
'description': 'A function that returns a random integer between a specified lower and upper bound.',
'properties': {'lb': {'description': 'Lower bound', 'title': 'Lb', 'type': 'integer'}, 'ub': {'description': 'Upper bound', 'title': 'Ub', 'type': 'integer'}},
'required': ['lb', 'ub'],
'test_field': 'this is a test',
'title': 'get_random_int',
'type': 'object'
}
|
Emulating Native Function Calling
n order to illustrate how to merge the signature models into the final response model to provide to the LLM, let’s create another dummy tool:
1
2
3
4
5
6
7
8
9
10
11
12 | class GenerateImageFunction(BaseFunction):
name = 'generate_image'
description = "A function that generates an image according to a given description and save it to specified location"
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
"image_description": "Description of the image to generate",
"output_path": "Path where to save the generated image"
}
def __call__(self, image_description: str, output_path: str, comment: str) -> str:
print(f'Generate an image using some fancy models with the following description:\n "{image_description}"')
return output_path
|
Let’s start with a very simple example to emulate native function calling.
We will provide additional features later.
Given a list of BaseFunction, we turn them into signature models and provide them as possible argument types in a Function model. Finally, because we want the LLM to be able to call several functions, we create a final model Functions that holds a list of Function. The model Functions is what will be used as response_model parameter.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | from typing import Union
from pydantic import BaseModel
tools = [RandomIntFunction, GenerateImageFunction]
FSMs = [to_function_signature_model(function=f) for f in tools]
class Function(BaseModel):
""" Represent a call to a function.
"""
args: Union[*FSMs]
class Functions(BaseModel):
"""
List of functions to be called
"""
functions: list[Function] = []
|
We are now ready to call some functions using our preferred LLM:
| messages = [
{
"role": "system",
'content': "You are a useful assistant"
},
{
"role": "user",
'content': "First, generate a random number between 3 and 10. Then, generate an image representing the city of Cracow in Poland. Finally, generate another random number between 30 and 50."
}
]
|
A word on structured output: the support for structured output is far from being unified as well. In fact, most closed-source LLM providers claim they support structured output, but they actually support a subset of OpenAPI specifications. For instance, Google Gemini or OpenAI models do not support a union of types. To make things worse, the support varies from provider to provider. The state of structured output for open-source models is much better, thanks to the amazing work from Outlines.
At Proofs, we developed our own LLM client to support all LLMs, from all major providers, but also infrastructure platforms such as Baseten or Groq, or even locally served LLMs via vLLM with a unified support for structured output and function calling. However, for this article, I will leverage the Instructor library as it is the easiest to work with, and the code provided here can easily be adapted to Anthropic, OpenAI, or any other supported provider.
1
2
3
4
5
6
7
8
9
10
11
12
13 | from anthropic import Anthropic
from instructor import from_anthropic
# Patch the Anthropic client with Instructor
client = instructor.from_anthropic(Anthropic())
response = client.messages.create(
max_tokens=1024,
messages=messages,
model="claude-3-5-sonnet-latest",
response_model=Functions,
)
print(response)
|
This results in the following structured output that perfectly solves the task by calling the three expected functions with proper parameters!
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | Functions(
functions=[
Function(args=get_random_int(lb=3, ub=10, comment='Generating initial random number between 3 and 10 as requested')),
Function(
args=generate_image(
image_description="Panoramic view of Cracow, Poland, showing the historic Market Square (Rynek Główny) with St. Mary's Basilica, the Cloth Hall (Sukiennice), and Wawel Castle in the background. The
scene captures the medieval architecture, cobblestone streets, and the city's distinctive Gothic and Renaissance buildings under a beautiful sky.",
output_path='cracow_image.png',
comment='Generating an image representing the city of Cracow with its most iconic landmarks'
)
),
Function(args=get_random_int(lb=30, ub=50, comment='Generating final random number between 30 and 50 as requested'))
]
)
|
It is now easy to call these functions on the client side:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | # Map the function sinature model to its actual functor class
tools_registry = dict(zip(FSMs, tools))
functions = response.functions
print("-" * 25)
for function in functions:
# Get the `BaseFunction` class
f = tools_registry[type(function.args)]
# Get the concrete arguments
args = function.args.model_dump()
print(f'Running "{f.__name__}" with args {args}')
# Instanciate the functor and call it with the arguments
output = f()(**args)
print(f"{output=}")
print("-" * 25)
|
This should result in something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | -------------------------
Running "RandomIntFunction" with args {'lb': 3, 'ub': 10, 'comment': 'Generating a random number between 3 and 10 as requested'}
output=4
-------------------------
Running "GenerateImageFunction" with args {'image_description': "The historic city of Cracow, Poland, showing the iconic Market Square (Rynek Główny) with St. Mary's Basilica, the Cloth Hall (Sukiennice), and
medieval architecture surrounding the square. The image should capture the city's Gothic and Renaissance buildings, cobblestone streets, and the unique architectural character of this UNESCO World Heritage site.",
'output_path': 'cracow_image.png', 'comment': 'Generating an image of Cracow, Poland as requested'}
Generate an image using some fancy models with the following description:
"The historic city of Cracow, Poland, showing the iconic Market Square (Rynek Główny) with St. Mary's Basilica, the Cloth Hall (Sukiennice), and medieval architecture surrounding the square. The image should
capture the city's Gothic and Renaissance buildings, cobblestone streets, and the unique architectural character of this UNESCO World Heritage site."
output='cracow_image.png'
-------------------------
Running "RandomIntFunction" with args {'lb': 30, 'ub': 50, 'comment': 'Generating a random number between 30 and 50 as requested'}
output=49
-------------------------
|
Perfect! We emulated function calling using only structured output!
One immediate advantage is being able to perform function calling for models that do not support it. Of course, the capability to comply with a JSON schema and fill the fields with interesting values will depend on the model, of course.
But, as mentioned in the introduction, there are many more advantages to user signature model function calling over native function calling. In particular, because we use Pydantic to generate the OpenAPI specifications, we can leverage every feature from the library.
Controlling the number of functions to be called
So far, the list could be empty, but we can enforce a minimum and maximum number of functions to be called using conlist:
For instance, if I constrain the list to at least one function call and provide a task that cannot be done with the provided tools, the LLM will still provide an answer, sometimes in an unexpectedly smart way:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | class Functions(BaseModel):
"""
List of functions to beb called
"""
functions: conlist(Function, min_length=1)
messages = [
{
"role": "system",
'content': "You are a useful assistant"
},
{
"role": "user",
'content': "You task is navigate to proofs.io and extract the background color"
}
]
|
| Functions(
functions=[
Function(
args=generate_image(
image_description="A screenshot showing webpage with 'proofs.io' URL and capturing its background color",
output_path='webpage_screenshot.png',
comment='I need to capture the webpage to analyze its background color'
)
)
]
)
|
| Functions(
functions=[
Function(
args=generate_image(
image_description="A screenshot showing webpage with 'proofs.io' URL and capturing its background color",
output_path='webpage_screenshot.png',
comment='I need to capture the webpage to analyze its background color'
)
)
]
)
|
| messages = [
{
"role": "system",
'content': "You are a useful assistant"
},
{
"role": "user",
'content': "How much is 2+2?"
}
]
|
| Functions(
functions=[
Function(args=get_random_int(lb=4, ub=4, comment="Since 2+2=4, I'm setting both lower and upper bounds to 4 to represent this mathematical fact, even though this is not the ideal way to perform addition"))
]
)
|
Let’s do something a bit more interesting. Let’s add a field task_done set by the LLM to indicate whether the task is done or not, and let’s constrain the max number of function calls to 2 while we know the task requires 3 calls. We can request a justification for observability.
| class Functions(BaseModel):
"""
List of functions to beb called
"""
functions: conlist(Function, min_length=0, max_length=2)
task_done: bool = Field(default=False, description="Indicate if the task requested by the user will be done by calling the `functions` that you suggest")
task_done_justification: str = Field(description="Justify why you think the task will be done or not after calling the `functions` that you suggest")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | Functions(
functions=[
Function(args=get_random_int(lb=3, ub=10, comment='Generating the first random number between 3 and 10 as requested')),
Function(
args=generate_image(
image_description="The historic city of Cracow, Poland, featuring the iconic St. Mary's Basilica, the medieval Market Square (Rynek Główny), and the Wawel Castle in the background",
output_path='cracow_image.png',
comment="Generating an image of Cracow's most recognizable landmarks and architecture"
)
)
],
task_done=False,
task_done_justification="The task cannot be fully completed with just these two function calls because the user requested three operations: 1) a random number between 3-10, 2) an image of Cracow, and 3) another
random number between 30-50. Due to the schema's limitation of maximum 2 function calls ('maxItems': 2), we can only execute the first two requests. The third request for a random number between 30-50 cannot be
fulfilled."
)
|
Now, the unconstrained version:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | Functions(
functions=[
Function(args=get_random_int(lb=3, ub=10, comment='Generating the first random number between 3 and 10 as requested')),
Function(
args=generate_image(
image_description="A panoramic view of Cracow, Poland, featuring the historic Market Square (Rynek Główny), St. Mary's Basilica with its distinctive towers, the Cloth Hall (Sukiennice), and Wawel
Castle in the background. The image should capture the medieval architecture and the unique atmosphere of this historic Polish city.",
output_path='cracow_image.png',
comment='Generating an image of Cracow with its most iconic landmarks and architecture'
)
),
Function(args=get_random_int(lb=30, ub=50, comment='Generating the second random number between 30 and 50 as requested'))
],
task_done=True,
task_done_justification='The task will be completed as all three requested operations will be performed in the correct order: first random number generation (3-10), then Cracow image generation, and finally
second random number generation (30-50). Each function call matches exactly what was requested in the task.'
)
|
This is amazing because it allows us to partially overcome the output token limitation. Imagine that a task would require 10 tools to be called, but unfortunately these 10 tools would need to fit in more than the maximum output token size of the model. We would then be able to limit the number to a reasonable amount of functions, and if the LLM states that the task is not done, we can call it again with the history of functions that were already proposed, until task_done=True.
Complex parameters for function calling
One major limitation with the current state of function calling is that most providers do not allow the use of complex types. By complex types, I mean types that are also defined by an OpenAPI spec themselves.
But in our case, because everything is done via structured output, we can use functions that have a Pydantic object as input!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | from enum import StrEnum
class ExtractionType(StrEnum):
DESIGN = "design"
LOGOTYPE = "logotype"
class Color(BaseModel):
color: str = Field(description="Hexadecimal color code", examples=["#FFFFFF"])
description: str = Field(
description="Description of the color",
examples=["This is the main color of the website, used for the background of the page."],
)
class WebsiteColorsExtractor(BaseFunction):
name = "extract_website_colors"
description = "Extract colors from a website, either from the whole website or the logotype."
properties = {
"comment": "Why are you extracting colors from an url?",
"url": "URL of an external website starting with https://",
"brand": "Official name of the brand, company or organization.",
"extraction_type": "Type of extraction: logotype or design",
"exclude_color": "A color to exclude."
}
def __call__(
self, comment: str, url: str, brand: str, extraction_type: str | ExtractionType = ExtractionType.LOGOTYPE, exclude_color: Color | None = None
) -> list[Color]:
print(f"Calling WebsiteColorsExtractor with {comment=}, {url=}, {brand=}, {extraction_type=}, {exclude_color=}")
|
At the moment, no LLM provider would allow such parameters (in particular the exclude_color), but to allow an agent to do more with the tools, we absolutely need to support more complex input because it means being able to do more complex tasks or the same task with better robustness and precision! For instance, on this small example, we can already see that we can control the input format of the color to enforce a hexadecimal code using examples and descriptions. We could also enforce it via a regex directly in Pydantic. We could likewise enforce a valid URL instead of a simple string, since Pydantic has a special type to represent URLs.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | Functions(
functions=[
Function(
args=extract_website_colors(
comment="Extracting colors from KFC's logotype to identify their brand colors, excluding white.",
url='https://www.kfc.com',
brand='KFC',
extraction_type='logotype',
exclude_color=Color(color='#FFFFFF', description='White color to be excluded from the extraction')
)
)
],
task_done=True,
task_done_justification="The task will be completed by calling the extract_website_colors function on KFC's website, specifically focusing on their logotype. I've set up the extraction to exclude white (which is commonly used in their logo) to focus on their distinctive red color scheme. The function will return the color palette used in their logotype."
)
|
Because the models used to perform the function calling are built dynamically, we can always add contextual information at runtime to influence the LLM’s output.
Let’s modify the function that transforms the BaseFunction into a Signature Model to include some contextual information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | def to_function_signature_model(function: BaseFunction, contextual_information: dict[str, str] | None = None) -> BaseModel:
# Remove `self` from the signature
S = signature(function.__call__, follow_wrapped=True)
params = [p.replace() for n, p in S.parameters.items() if n != 'self']
new_s = Signature(parameters=params, return_annotation=S.return_annotation)
# Build the field with the available info from the signature and the object itself
pydantic_fields = {k:defaultdict() for k in new_s.parameters.keys()}
for param_name, param in new_s.parameters.items():
if desc := function.properties.get(param_name):
pydantic_fields[param_name]['description'] = desc
if param.default != Signature.empty:
pydantic_fields[param_name]['default'] = param.default
json_schema_extra = {'description': function.description.strip()}
if contextual_information:
json_schema_extra.update(contextual_information)
model: BaseModel = create_model(
function.name,
__config__=ConfigDict(json_schema_extra=json_schema_extra),
**{param_name: (param.annotation, Field(**pydantic_fields[param_name])) for param_name, param in new_s.parameters.items()}
)
return model
|
And let’s try it so that the request will take into account some contextual information when suggesting functions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | contextual_information = {
'current_season': 'winter',
'user_preferences': "THE USER IS DEADLY ALLERGIC TO ANY REFERENCE TO KFC. NEVER MENTION IT. ALWAYS USE AN ALTERNATIVE FAST-FOOD"
}
tools = [RandomIntFunction, GenerateImageFunction, WebsiteColorsExtractor]
FSMs = [to_function_signature_model(function=f, contextual_information=contextual_information) for f in tools]
...
messages = [
{
"role": "system",
'content': "You are a useful assistant"
},
{
"role": "user",
'content': "Generate a picture of Cracow in Poland during the current season. Extract the colors from the logotype of KFC's website. Exclude the color white."
}
]
|
As we can see, the function did not follow the prompt but properly used the contextual information to NOT call anything related to KFC. It also leveraged the current season information to generate the image. Of course, this could also be obtained by prompt engineering, templating the prompt, and injecting the information using Jinja2 or any other template mechanism, but there are a couple of advantages here:
-
The control is limited to the function calling and can even be done per function.
-
Not having to modify or template the prompt makes it easier to maintain and version.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | Functions(
functions=[
Function(
args=extract_website_colors(
comment="I will extract colors from McDonald's website instead, as there is a user preference indicating an allergy to KFC references. McDonald's is a suitable alternative fast-food chain.",
url='https://www.mcdonalds.com',
brand="McDonald's",
extraction_type='logotype',
exclude_color=Color(color='#FFFFFF', description='White color to be excluded from the extraction')
)
),
Function(
args=generate_image(
image_description="A winter scene of Cracow, Poland, featuring the iconic St. Mary's Basilica and the Cloth Hall in the Main Market Square covered in snow. The scene captures the medieval
architecture with snow-capped roofs, and people bundled up walking through the square. The winter atmosphere includes some Christmas decorations and warm lights from the surrounding buildings.",
output_path='cracow_winter.png',
comment='Generating an image of Cracow during winter (current season) to fulfill the request'
)
)
],
task_done=True,
task_done_justification="The task will be completed successfully because: 1) We're extracting colors from McDonald's website (respecting user preferences) while excluding white as requested, and 2) We're
generating a seasonally appropriate winter image of Cracow, Poland, incorporating the city's most recognizable landmarks and winter atmosphere."
)
|
Dependencies & Placeholders
The most useful feature that is missing from native function calling is the management of dependencies between function calls. In fact, native function calling looks prehistoric in comparison to what state-of-the-art models are capable of achieving. Reasoning models are capable of planning dozens of steps. Yet, it is not technically possible to have them execute these steps properly in one call.
Example: Image Upload with Dependencies
Let’s create a scenario where we generate an image, upload it to a some service using a JWT token, and then share the uploaded image using an ID returned when the upload is successfully executed.
Let’s create some toy tools:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56 | class ObtainToken(BaseFunction):
name = 'obtain_token'
description = "Generate a new JWT token to access our API. It returns the JWT as a string."
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
}
def __call__(self, comment: str) -> str:
print(f'Get a new token')
return "password123"
class GenerateImageFunction(BaseFunction):
name = 'generate_image'
description = "A function that generates an image according to a given description and save it to specified location"
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
"image_description": "Description of the image to generate",
"output_path": "Path where to save the generated image",
"collage": "list of path to local images files that should be used to generate the image, like a collage"
}
def __call__(self, image_description: str, output_path: str, collage: list[str], comment: str) -> str:
print(f'Generate an image using some fancy models with the following description:\n "{image_description}"')
print(f'Collage time!', collage)
return output_path
class UploadImage(BaseFunction):
name = 'upload_image'
description = "Upload an image to our backend. REQUIRE A JWT TOKEN! It returns the ID of the uploaded image."
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
"jwt_token": "JWT tokent to authenticate",
"path": "Path of the image to upload"
}
def __call__(self, jwt_token: str, path: str, comment: str) -> str:
print(f'Upload the image {path}')
print(f'JWT Token: {jwt_token}')
return 'image-id-1234' if jwt_token == 'password123' else 'failed to upload the image'
class ShareImage(BaseFunction):
name = 'share_image'
description = "Share the image to a given email IFF the image was already uploaded."
properties: dict[str: str] = {
"comment": "Why are you calling this function?",
"image_id": "ID of the image",
"email": "email to which we will send the image"
}
def __call__(self, image_id: str, email: str, comment: str) -> str:
print(f'Share image ID {image_id}')
print(f'Email: {email}')
return 'SENT' if image_id == 'image-id-1234' else 'SOMETHING WENT WRONG'
|
A simple task like “Generate an image of Krakow, upload it to the backend and then share it with our favorite customer” would require calls with temporal dependency:
- Generate an image
- Get a token
- Upload the image using the token
- Share the image using the image ID obtained during the upload
Although this is simple for a human, it cannot be done in one call by any current LLM because the call to one function requires the output from another. This is not only an implicit temporal dependency, but an explicit one.
To handle dependencies between functions, we only have to modify our Function object and the description of Functions. We add a notion of parent-child relationship such that the list of functions to call can be interpreted as a DAG:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | class Function(BaseModel):
""" Represent a call to a function.
"""
function_id: int = Field(description="ID of the function call. It is unique for each call. Functions are called sequentially by growing ID withing a sequence.")
args: Union[*FSMs]
parents_ids: list[int] = Field(default=[], description="ID of the functions that needs to be called before this one")
children_ids: list[int] = Field(default=[], description="ID of the functions that are to be called after this one")
class Functions(BaseModel):
"""
List of functions representing an direct acyclic graph where a node is a function and an edge a dependency between two functions (one must be called before the other)
"""
functions: list[Function] = []
task_done: bool = Field(default=False, description="Indicate if the task requested by the user will be done by calling the `functions` that you suggest")
task_done_justification: str = Field(description="Justify why you think the task will be done or not after calling the `functions` that you suggest")
|
The LLM can now return a structured output with dependencies. Instead of being a naive list of tools, the list can be interpreted as a graph and the scheduling execution done accordingly:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58 | Functions(
functions=[
Function(function_id=1, args=obtain_token(path='jwt_token.txt', content='jwt_token', comment='Need to obtain a JWT token first to be able to upload the image later'), parents_ids=[], children_ids=[3]),
Function(
function_id=2,
args=generate_image(
image_description="A beautiful panoramic view of Krakow, Poland, showing the historic Market Square (Rynek Główny) with St. Mary's Basilica, the Cloth Hall, and medieval architecture under a vibrant
blue sky",
output_path='krakow_image.jpg',
collage=[],
comment='Generating a scenic image of Krakow that will be appealing to our customer'
),
parents_ids=[],
children_ids=[3]
),
Function(
function_id=3,
args=upload_image(jwt_token='jwt_token', path='krakow_image.jpg', comment='Uploading the generated Krakow image to our backend using the JWT token'),
parents_ids=[1, 2],
children_ids=[4]
),
Function(
function_id=4,
args=share_image(image_id='krakow_image_id', email='favorite.customer@email.com', comment='Sharing the uploaded Krakow image with our favorite customer'),
parents_ids=[3],
children_ids=[]
)
],
task_done=True,
task_done_justification='The task will be completed successfully because we are executing all the necessary steps in the correct order: 1) obtaining the JWT token for authentication, 2) generating a beautiful
image of Krakow, 3) uploading the image to our backend using the token, and finally 4) sharing the uploaded image with our favorite customer. The dependencies between functions are properly set to ensure the correct
sequence of operations.'
)
-------------------------
Running "ObtainToken" with args {'path': 'token.txt', 'content': 'jwt_token', 'comment': 'Need to obtain a JWT token first to be able to upload the image later'}
Get a new token
output='password123'
-------------------------
Running "GenerateImageFunction" with args {'image_description': "A panoramic view of Krakow, Poland, showcasing the historic Market Square (Rynek Główny) with St. Mary's Basilica and the Cloth Hall in the center,
surrounded by colorful medieval buildings under a beautiful blue sky", 'output_path': 'krakow.png', 'collage': [], 'comment': "Generate a beautiful image of Krakow's most iconic landmarks"}
Generate an image using some fancy models with the following description:
"A panoramic view of Krakow, Poland, showcasing the historic Market Square (Rynek Główny) with St. Mary's Basilica and the Cloth Hall in the center, surrounded by colorful medieval buildings under a beautiful blue
sky"
Collage time!
[]
output='krakow.png'
-------------------------
Running "UploadImage" with args {'jwt_token': 'jwt_token', 'path': 'krakow.png', 'comment': 'Upload the generated image of Krakow to the backend'}
Upload the image krakow.png
JWT Token: jwt_token
output='failed to upload the image'
-------------------------
Running "ShareImage" with args {'image_id': 'krakow.png', 'email': 'favorite.customer@email.com', 'comment': 'Share the uploaded Krakow image with our favorite customer'}
Share image ID krakow.png
Email: favorite.customer@email.com
output='SOMETHING WENT WRONG'
-------------------------
|
We can clearly see that, although the dependencies between the tasks are handled properly, the execution of the functions still fails because the next function’s input depends on the previous one’s output!
To handle this case, we need a placeholder system. Developing a robust placeholder system to handle the replacement at runtime is not a trivial task, so we will only build a simple version here.
First, we create a placeholder type:
| class FunctionOutputRef(BaseModel):
""" Represent a reference to the output of a function execution.
It is used to indicate that the output of a functionc all should be used as the input of the next one.
"""
function_id: int = Field(description="ID of the function for which we reference the output")
|
Then, we need to modify the annotation for the function signature model during its creation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 | def to_function_signature_model(function: BaseFunction, contextual_information: dict[str, str] | None = None) -> BaseModel:
# Remove `self` from the signature
S = signature(function.__call__, follow_wrapped=True)
params = [p.replace() for n, p in S.parameters.items() if n != 'self']
new_s = Signature(parameters=params, return_annotation=S.return_annotation)
# Build the field with the available info from the signature and the object itself
pydantic_fields = {k:defaultdict() for k in new_s.parameters.keys()}
for param_name, param in new_s.parameters.items():
if desc := function.properties.get(param_name):
pydantic_fields[param_name]['description'] = desc
if param.default != Signature.empty:
pydantic_fields[param_name]['default'] = param.default
json_schema_extra = {'description': function.description.strip()}
if contextual_information:
json_schema_extra.update(contextual_information)
model: BaseModel = create_model(
function.name,
__config__=ConfigDict(json_schema_extra=json_schema_extra),
**{param_name: (Union[param.annotation, FunctionOutputRef], Field(**pydantic_fields[param_name])) for param_name, param in new_s.parameters.items()}
)
return model
|
Notice that we change the type of the original parameter to Union[param.annotation, FunctionOutputRef], allowing any parameter to receive a placeholder.
At this stage, the LLM is already capable of putting the proper placeholder where needed:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 | Functions(
functions=[
Function(function_id=1, args=obtain_token(path='token.txt', content='my_jwt_token', comment='Need to get a JWT token first to be able to upload the image later'), parents_ids=[], children_ids=[3]),
Function(
function_id=2,
args=generate_image(
image_description="A panoramic view of Krakow, Poland, showcasing its historic medieval architecture, with the iconic Wawel Castle, St. Mary's Basilica, and the main market square (Rynek Główny)
visible. The image should capture the city's Gothic and Renaissance buildings under a beautiful sky.",
output_path='krakow_image.jpg',
collage=[],
comment="Generating a beautiful image of Krakow that we'll later upload and share"
),
parents_ids=[],
children_ids=[3]
),
Function(
function_id=3,
args=upload_image(jwt_token=FunctionOutputRef(function_id=1), path='krakow_image.jpg', comment='Uploading the generated image of Krakow to our backend'),
parents_ids=[1, 2],
children_ids=[4]
),
Function(
function_id=4,
args=share_image(image_id=FunctionOutputRef(function_id=3), email='favorite.customer@email.com', comment='Sharing the uploaded Krakow image with our favorite customer'),
parents_ids=[3],
children_ids=[]
)
],
task_done=True,
task_done_justification='The task will be completed successfully because the sequence of functions will: 1) obtain a JWT token for authentication, 2) generate a beautiful image of Krakow, 3) upload the generated
image to our backend using the JWT token, and finally 4) share the uploaded image with our favorite customer via email. The functions are properly ordered with correct dependencies to ensure each step is completed
before the next one begins.'
)
|
All we need to do now is detect the placeholders at runtime and resolve them. To do so, let’s store the output of each call progressively and replace the placeholder by the referenced output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | functions = response.functions
print("-" * 25)
tool_outputs = {}
for function in functions:
# Get the `BaseFunction` class
f = tools_registry[type(function.args)]
# Get the concrete arguments
args = function.args.model_dump()
for arg_name, arg_value in function.args:
if isinstance(arg_value, FunctionOutputRef):
new_value = tool_outputs.get(arg_value.function_id) # many checks skipped!
args[arg_name] = new_value
print(f'Placeholder replacement for argument {arg_name} from {arg_value} -> {new_value}')
print(f'Running "{f.__name__}" with args {args}')
# Instanciate the functor and call it with the arguments
output = f()(**args)
tool_outputs[function.function_id] = output
print(f"{output=}")
print("-" * 25)
|
This leads to the following execution:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | -------------------------
Running "GenerateImageFunction" with args {'image_description': "A panoramic view of Krakow, Poland, showing the historic Market Square (Rynek Główny) with St. Mary's Basilica and the Cloth Hall (Sukiennice) during
a beautiful sunny day, with people walking around and traditional horse carriages in the foreground", 'output_path': 'krakow_image.jpg', 'collage': [], 'comment': "Generating a beautiful image of Krakow's most
iconic location"}
Generate an image using some fancy models with the following description:
"A panoramic view of Krakow, Poland, showing the historic Market Square (Rynek Główny) with St. Mary's Basilica and the Cloth Hall (Sukiennice) during a beautiful sunny day, with people walking around and
traditional horse carriages in the foreground"
Collage time!
[]
output='krakow_image.jpg'
-------------------------
Running "ObtainToken" with args {'path': 'jwt_token.txt', 'content': 'my_secure_jwt_token', 'comment': 'Getting JWT token for authentication before uploading the image'}
Get a new token
output='password123'
-------------------------
Placeholder replacement for argument jwt_token from function_id=2 -> password123
Running "UploadImage" with args {'jwt_token': 'password123', 'path': 'krakow_image.jpg', 'comment': 'Uploading the generated Krakow image to the backend'}
Upload the image krakow_image.jpg
JWT Token: password123
output='image-id-1234'
-------------------------
Placeholder replacement for argument image_id from function_id=3 -> image-id-1234
Running "ShareImage" with args {'image_id': 'image-id-1234', 'email': 'favorite.customer@example.com', 'comment': 'Sharing the Krakow image with our favorite customer'}
Share image ID image-id-1234
Email: favorite.customer@example.com
output='SENT'
-------------------------
|
Perfect! We are now able, in one single LLM call, to generate many function calls, manage temporal dependencies between them, and resolve dependencies between inputs and outputs!
Conclusion
We have barely scratched the surface of what is possible when using signature model mode for function calling.
For instance, we used only stateless functions, but because we encapsulated the function in a BaseFunction class, we can also manage state by instantiating the class and storing a reference to it. We can also leverage async, generators, and various other mechanisms offered by Python.
For the execution workflow, we could manage dependencies more precisely to know which functions can be called in parallel, which can be grouped in a batch, vectorized, etc.
Finally, function calling usually do not care about the return type but with signature model function calling, we can include the output type that can be another Pydantic object and develop a more complex placeholder system where the placeholder can actually refer to a particular member of this pydantic structure.
I really believe function calling should be in a much better state than it is right now, and this should probably involve Signature Model function calling. I know that the model providers would like to offer similar features embedded in the model, but I do not believe they will ever be able to provide a generic server-side interface that could suit all applications. Managing the tools within an agent or an agentic workflow is application-specific.
The solution proposed in this article is fairly generic and extensible. It can be used by any LLM as long as structured output is available, and the capabilities only grow with the LLM’s abilities. Better models, such as reasoning models, allow populating an enormous number of functions in one call, managing all the dependencies and execution modalities. For us, this is a game-changer because the associated cost is drastically reduced!